My Agent Needed a Memory. I Already Had One.
I’ve been using Obsidian as a second brain for years (vault). The thought of being able to hook an agent up to it has always been attractive to me.
For every project I work on, I keep a running log: what I was doing that day, a bit of why I wanted to do it, and any problems I ran into, so that if I ever come back I can understand where I left off. Or even just use it as a reference. Having all of that information siloed by project in the second brain was helpful.
So when I came across OpenClaw and got excited at the idea of having it act as a personal assistant to help me manage time across all the different things I’m interested in, the first thing I wanted was for the agent to be able to reach into that brain.
If something comes up in conversation: a new article, an idea I haven’t thought about yet; the agent should be able to link it back to things it already knows I care about.
I can send it a link I’ve just come across and say “this makes me think of one of my projects, what can I do to connect them?”, it should be able to go and look inside the vault, find the relevant notes, and see my own thoughts as I was going through it.
For morning briefings, the agent would have a log of what I was working on the day before, it can enrich that context. A queryable second brain is useful for me directly too. It’s kind of both for me and the agent.
Currently my second brain lives on a Raspberry Pi on my windowsill. I have it set up with obsidian-livesysnc So I can have it instantly mirrored between my Mac, Phone and now for my agent (Sill)
If I’m doing work and writing in my notes, I can ask the agent something that references something I’ve just written. It could even produce an artefact that I read on my phone, and I can then prompt it from my phone to look at something else in the vault and produce another artefact I’ll read later on my laptop. That’s the kind of synergy I was looking for in a solution like this.
Sill-rag is the piece that makes this possible. It’s a small Python service that syncs my Obsidian vault in real time, chunks and embeds every note and past session transcript, and serves the result via a hybrid search API.
When I drop a note in Obsidian from my phone, Sill-rag ensures the agent can find it within a few seconds.
1. Architecture
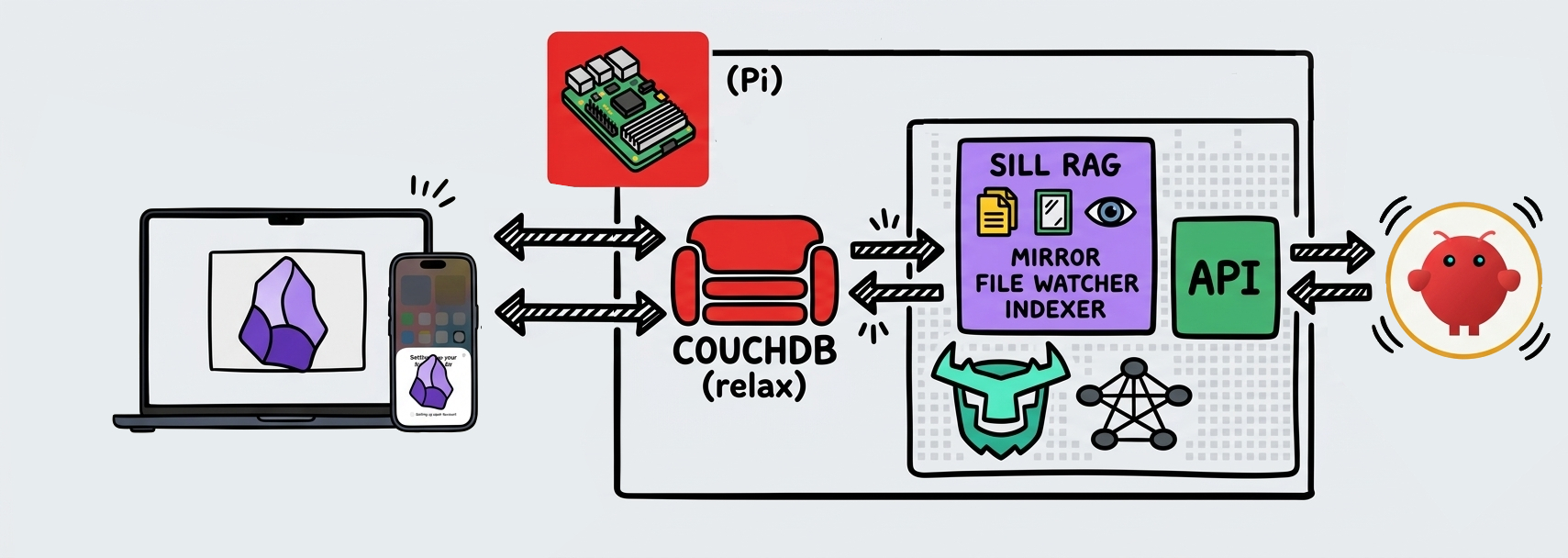
Nano Bannana tried its best to replicate my vision.
Three services run concurrently inside a single Python process: a mirror that maintains bidirectional sync between CouchDB and the local filesystem; a watcher that picks up file changes and feeds them into the indexer; and an HTTP server (FastAPI) that the agent queries.
I have a thing for SQLite.
It’s just this really simple, lightweight solution that has all I could ever really want out of a database for the kind of projects I work on. Much easier than spinning up a Docker container with Postgres, no third-party service where I have to make an account and worry about that kind of thing. Usually I use it for small web apps I might deploy even temporarily. So not having to rely on anything external felt like exactly the right fit here.
I came across Turso through articles about what they’re building and immediately wanted to find an excuse to use it in a project. This was that excuse. Beyond the simplicity of SQLite, Turso adds a Tantivy-backed full-text search engine and an ANN vector index.
I’m even excited about where they’re taking things AgentFS looks like it could reshape how stacks like this one are built, and I’ll be coming back to that.
Obsidian’s graph view is what drew me to the tool in the first place. I wanted a similar representation in this memory layer.
As i had been exploring OpenClaw, I had peered into it to add a Langfuse integration so I could trace what the agent was thinking and self-hosted that too. This was taking up more resources than I expected so my inclination to go for dockerised neo4j was going to be too resource heavy.
Enter Graphqlite. SQLite-backed, with a Cypher-like API, so if I want to query my second brain’s relationships from somewhere else I can do it with Cypher rather than some other arcane solution where we traverse the files as we see the wikilinks.
I discovered the hard way that Turso’s Tantivy index structures conflict with Graphqlite’s internal SQLite schema. Hence why they got separated. A more unified solution would be beautiful; this is the pragmatic split.
2. Real-time Sync: Hooking into LiveSync
LiveSync uses CouchDB under the hood and exposes a changes feed. That’s what this service taps into. The mirror long-polls the changes feed with a timeout. When a change arrives, it reconstructs the updated file from the way LiveSync stores documents internally — f: prefix docs hold file metadata and a list of child chunk IDs, while h: prefix docs hold the actual content fragments:
// f: metadata doc
{
"_id": "f:projects/sill-rag.md",
"path": "projects/sill-rag.md",
"children": ["h:a1b2c3", "h:d4e5f6"]
}
// h: content chunk doc
{
"_id": "h:a1b2c3",
"data": "# sill-rag\n\nA hybrid RAG service..."
}
The mirror fetches the child chunks in sequence and concatenates them to reconstruct the file on disk. The tricky bit is write-loop prevention: when the mirror writes a file to disk, that write triggers a watchdog file event, which would naively push the change back to CouchDB. To break the loop, every path the mirror writes is tracked in a mirror_writes set for a short suppression window, with a 500ms debounce to collapse inotify bursts. A SHA256 hash of the last mirror-written content catches genuine divergence. If the local file has drifted independently, it gets saved to a conflicts directory before being overwritten.
3. Schema
Two tables in sill.db. files tracks each indexed document with its path, SHA256 hash, and type (vault_md or session_jsonl). chunks holds the actual searchable content: the text, a JSON metadata blob, and an F32_BLOB(1536) column for the embedding vector.
IDs are deterministic: file_id = SHA256(path)[:32], chunk_id = SHA256(file_id:idx)[:32]. Consistent across restarts, no UUID generation required.
The Graphqlite graph stores nodes as File records with {id, path, title} properties, connected by LINKS_TO edges representing wikilink references.
4. Chunking
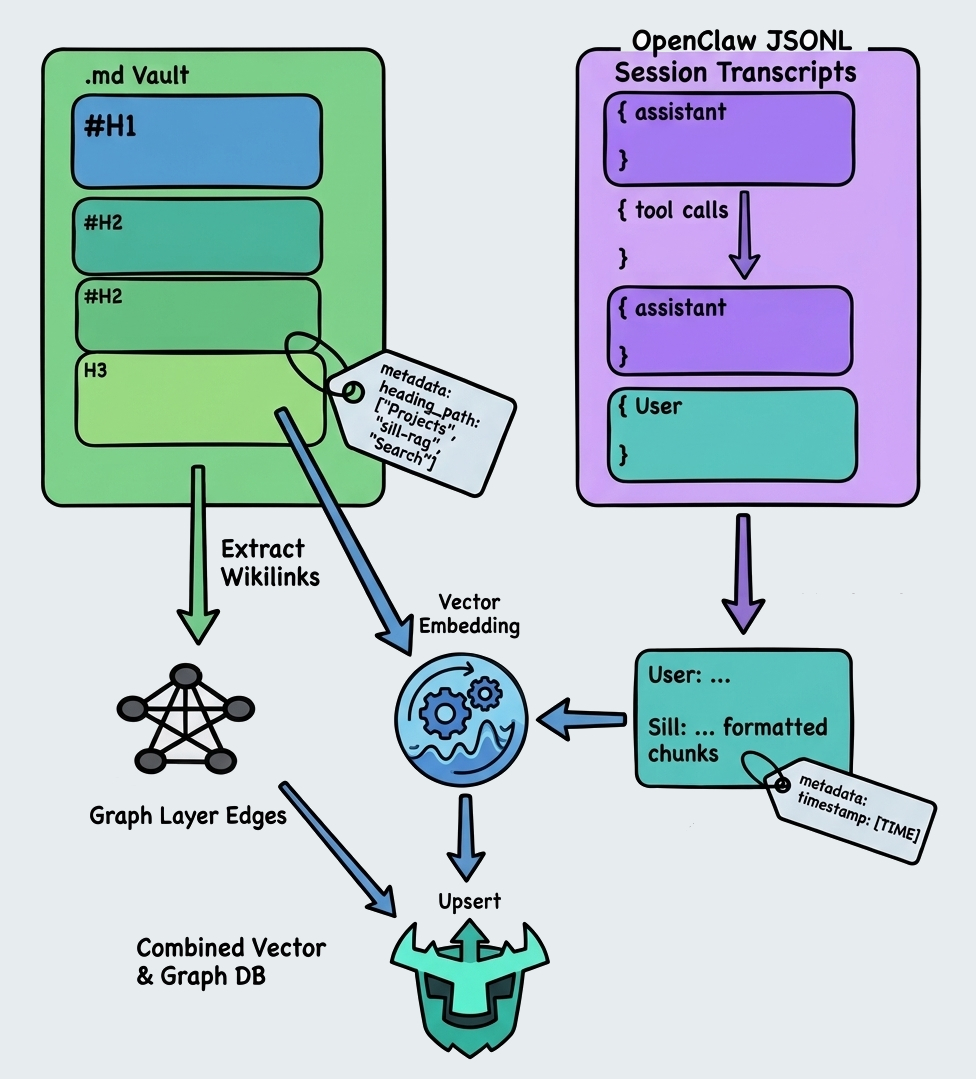
Genuinly surprised it maintained the irregularity of my reference diagram so well.
Two content types, two strategies.
Markdown vault notes are split along their own heading hierarchy, H1 down to H3. Each chunk carries its breadcrumb path as metadata (heading_path: ["Projects", "sill-rag", "Search"]). Wikilinks are extracted during chunking and passed to the graph layer as edges.
The vault structure I’m building towards has daily notes from my OpenClaw sessions, plus a parent folder per project. Each with a Dataview dashboard and its own set of notes tracking my work on that project. If something that comes up in a daily note references a file in the vault, that link gets captured as a graph edge. I can then pick up those relationships that might be lost to pure vector search, increasing the relevance the agent can give me whenever we’re interacting. The graph layer encodes the structure of how I actually organise my thinking, not just what’s written in the text.
Session transcripts are OpenClaw JSONL files. A stream of typed events: user messages, assistant responses, tool calls, internal reasoning. The chunker pairs consecutive user and assistant turns into single chunks, skipping tool events and internal thinking. The result is User: ...\n\nSill: ... formatted chunks, each carries a session timestamp.
5. Hybrid Search: BM25 + Vector + Graph
Three signals get fused.
Vector search embeds the query and runs it against Turso’s ANN index.
Full-text search uses Turso’s Tantivy BM25 engine.
Graph expansion seeds a 2-hop breadth-first traversal of the wikilink graph from the top 5 vector results. It surfaces related notes that may not match the query directly but are structurally adjacent to notes that do.
The three ranked lists get merged with Reciprocal Rank Fusion — my go-to for this kind of thing.
It was a success. I could update my notes from anywhere and have the agent be able to access them within seconds. I’m closing in on having the vault structured in a way that supports my use case, acting as my personal tracker for all the things I’m interested in, with the agent able to navigate it alongside me. My second brain is getting more useful by the day.